Main Window
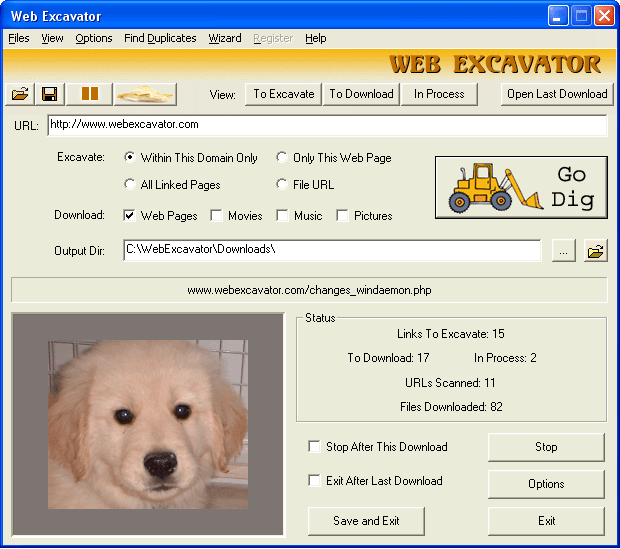
- Toolbar:
- Save: Save download lists.
- Load: Select previously saved file.
- Pause: Pause downloading files. Select again to unpause.
- Empty 'To Download' List: Removes all the files in the 'To Download' list.
- View 'Links To Excavate' Queue: View Sites that are in the 'Links To Excavate' list (you can remove them here).
- View 'To Download' Queue: View Files that are in the download list (you can remove them here).
- View 'In Process': View Files that are being downloaded list (you can remove them here).
- Open Last Download: Opens the last completed download.
- URL: Here type the full URL of the web site or file you want to download. To download it, press the 'Go Dig' button. The up and down arrows display any previously excavated URLs.
- Excavate: The ways in which Web Excavator can process a URL.
- Within this Domain Only: Download and process all pages that can be found in this domain (webexcavator.com is an example of a domain). This can be refined by the options described in the section below.
- Only This Web Page: Just download and process this one page.
- All Linked Pages: Download and process all links found on all web pages. See Options section below to see how your search can be restricted (otherwise you could download the entire world wide web!).
- File URL: Download the given file.
- Download: The types of files to download.
- Web Pages: Download web pages (i.e. all files except some that are potentially harmful).
- Movies: Download movies types.
- Music: Download music types.
- Pictures: Download pictures types.
- Go Dig: Press this button to start downloading!
- Output Dir: Where the downloaded files will be saved to.
- Clicking on the image will open that graphic in your default viewer.
- Status
- Links To Excavate: The number of web pages left to process.
- To Download: The number of files queued for download. If this number is below 24 (this can be set in advanced options) it will process the next 'Links To Excavate'.
- In Process: The number of files currently being processed (either looking for links or downloading files).
- URLs Scanned: The number of URLs that have been scanned this session.
- Files Downloaded: The number of completed downloads this session.
- Stop After This Download: Stops the program from processing a Web site after what is currently downloading has completed.
- Stop: Stops the program from processing a Web site immediately.
- Exit After last Download: Exits the program once the last URL has been scanned and the last download completed.
- Options: Brings up the options dialog (see below)
- Save And Exit: Saves the current download lists and then exits the program.
- Exit: Exits the program, but will continue downloading what it started in the background.
- Excavate: The ways in which Web Excavator can process a URL.